



Компания Nvidia представила открытую большую языковую модель (LLM) Nemotron-4 340B. Она может применятся в здравоохранении, финансах, производстве и розничной торговли.
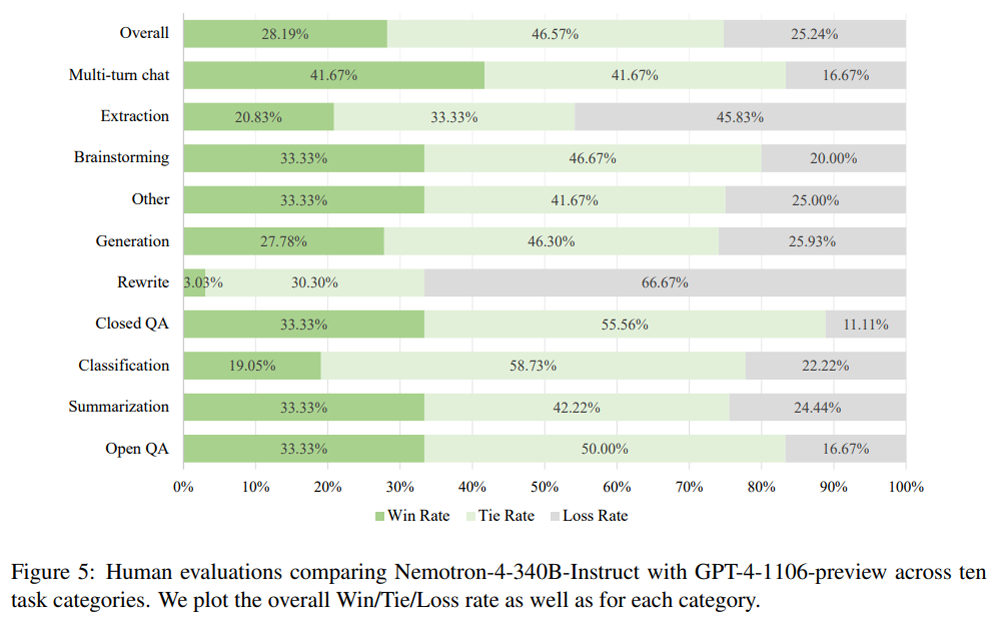 Nemotron-4 340B обучалась на 50+ естественных языках и 40+ языках программирования — всего на 9 трлн. токенах. Архитектура модели построена на Grouped-Query Attention (GQA) и Rotary Position Embeddings (RoPE). Но длина контекста ограничена 4096 токенами.
Nemotron-4 340B обучалась на 50+ естественных языках и 40+ языках программирования — всего на 9 трлн. токенах. Архитектура модели построена на Grouped-Query Attention (GQA) и Rotary Position Embeddings (RoPE). Но длина контекста ограничена 4096 токенами.
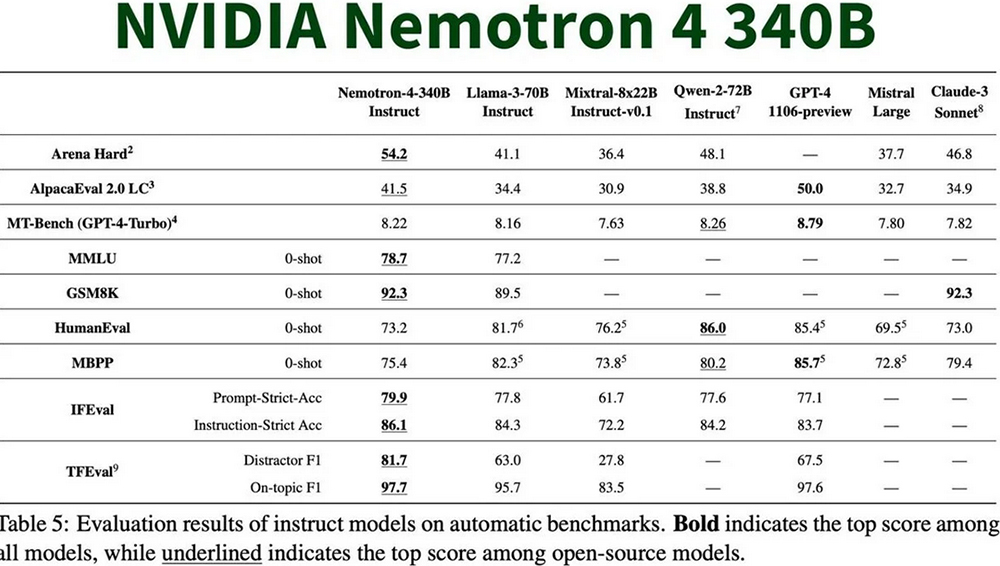
Модель представлена в трех версиях: Nemotron-4-340B-Base, Nemotron-4-340B-Instruct и Nemotron-4-340B-Reward.
- Base — предназначена для генерации синтетических данных;
- Instruct — для чата и выполнения инструкций;
- Reward — base-модель с дополнительным линейным слоем для обученияс использованием нового reward-подхода.
Модели оптимизированы для работы с платформой Nvidia NeMo и вывода с помощью библиотеки TensorRT-LLM с открытым исходным кодом. Nemotron-4 340B распространяется под лицензией Nvidia Open Model License Agreement, разрешающая коммерческое использование.
Nemotron-4 340B уже доступна для загрузки с Hugging Face.





