



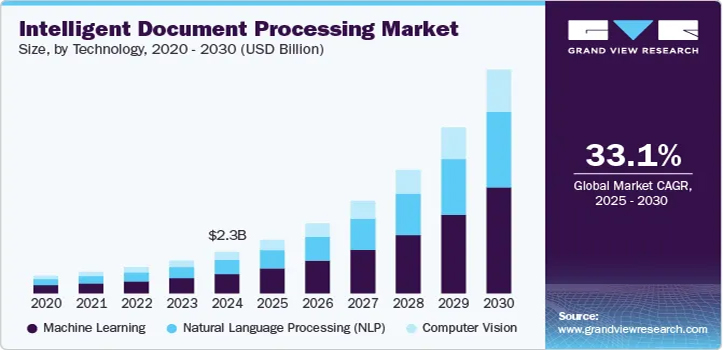
Прогрессивно мыслящие организации находятся в поиске технологий, которые оптимизируют операции, сокращают количество ошибок и повышают производительность. Одна из таких технологий — интеллектуальная обработка документов (Intelligent Document Processing — IDP), основанная на искусственном интеллекте. IDP позволяет организациям любого размера отказаться от дорогостоящих и неэффективных ручных процессов, повысить точность обработки данных и более эффективно использовать имеющихся сотрудников. Объем рынка IDP в 2024 году составил 2 млрд. долларов, а к концу 2037 года, согласно прогнозам, он достигнет 62 млрд. долларов, увеличиваясь в среднем на 30% в течение прогнозируемого периода. В 2025 году объем отрасли интеллектуальной обработки документов оценивается в 2,8 млрд. долларов. Это свидетельствует о том, что компании быстро внедряют технологии обработки документов, поскольку потребность в автоматизации сложных сценариев продолжает расти. Период экономической нестабильности еще больше повышает спрос на технологии обработки документов. Именно в это время государственные и частные организации стремятся повысить эффективность и сократить расходы, сокращая неэффективные ручные процессы.
Интеллектуальная обработка документов появилась как технология, меняющая правила игры, которая использует искусственный интеллект, машинное обучение и оптическое распознавание символов (OCR) для автоматизации и улучшения рабочих процессов, связанных с документами. Проще говоря, IDP — это использование искусственного интеллекта для сбора, извлечения и обработки данных из документов. В отличие от традиционной обработки документов, которая часто требует ручного вмешательства, системы IDP могут автоматически обрабатывать сложные документы, сокращая человеческие ошибки и повышая эффективность. Давайте рассмотрим, как IDP трансформирует отрасли.
Эволюция обработки документов
Исторически предприятия полагались на ручные процессы для обработки документов, что часто приводило к неэффективности, ошибкам и задержкам. Такие задачи, как сортировка документов, извлечение ключевых данных и ввод информации в базы данных, отнимали много времени и были подвержены ошибкам. По мере роста организаций рос и объем документов, что делало традиционную обработку документов все более неэффективной. Появление IDP произвело революцию в том, как предприятия справляются с документами. Объединяя технологию OCR с искусственным интеллектом и машинным обучением, IDP не только извлекает данные, но и понимает контекст документа, делая его мощным инструментом для автоматизации задач, ориентированных на работу с документами.
Переход от ручной обработки документов к автоматизированной обусловлен потребностью в большей эффективности. IDP может обрабатывать тысячи документов за небольшое время, что не только ускоряет рабочие процессы, но и позволяет сотрудникам сосредоточиться на более важных задачах, таких как принятие стратегических решений.
Ключевые компоненты IDP
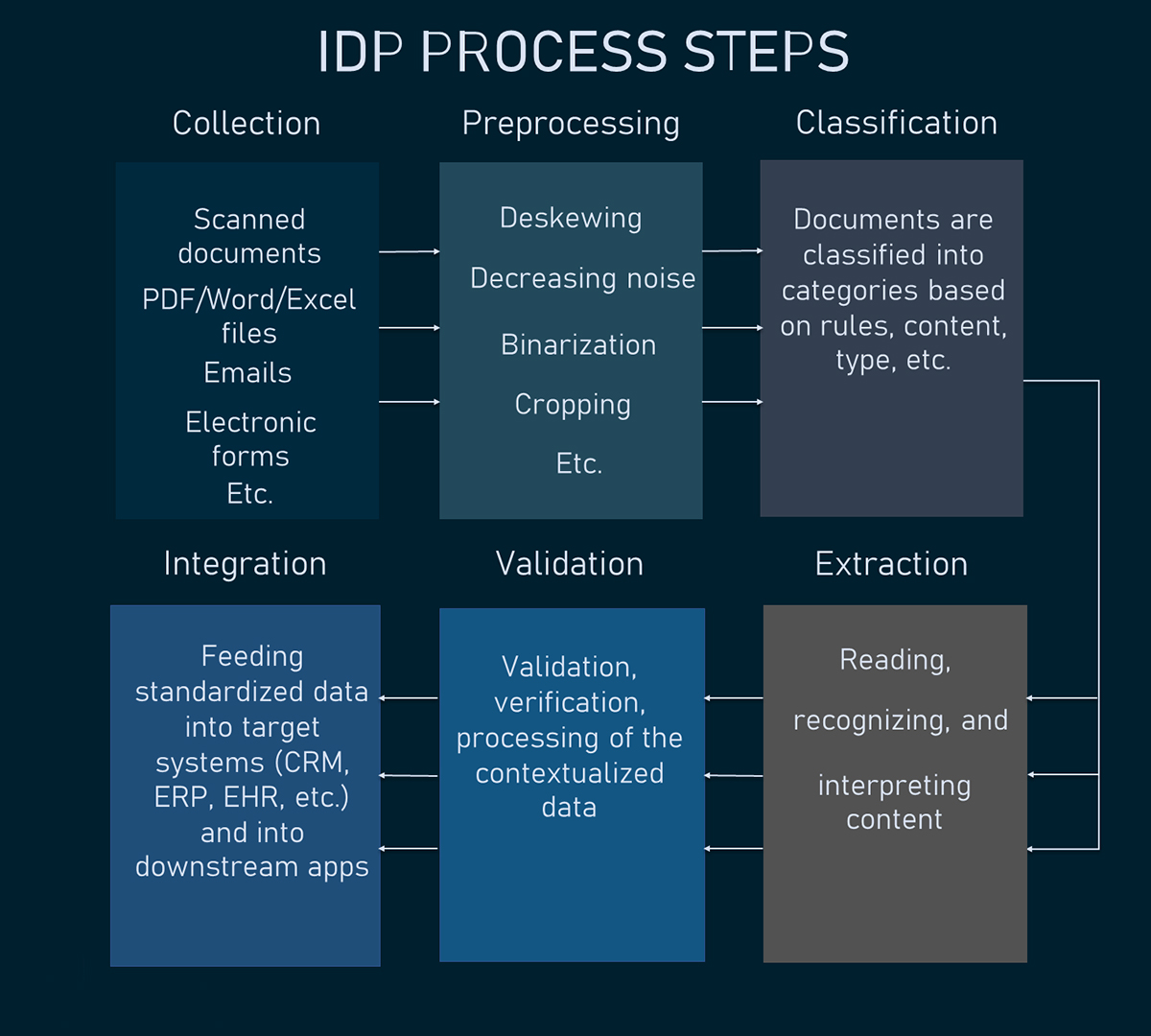
IDP объединяет несколько технологий предоставляя комплексные решения для автоматизации документов. Давайте разберем основные компоненты:
- Оцифровка и захват документов: Первый шаг в процессе IDP включает захват документов и преобразование их в цифровой формат. Это может включать сканирование бумажных документов или обработку уже цифровых файлов.
- Извлечение данных (OCR): Технология OCR сканирует документ и извлекает текст. Передовые решения IDP используют искусственный интеллект и машинное обучение, чтобы не только читать текст, но и точно его интерпретировать, независимо от форматирования или почерка.
- Классификация документов: Системы IDP могут автоматически классифицировать документы на основе их содержания, например, счета-фактуры, контракты или медицинские записи. Этот этап классификации имеет решающее значение для организации и управления большими объемами документов.
- Проверка и обработка данных: После извлечения данных выполняется проверка их точности. Алгоритмы искусственного интеллекта сравнивают извлеченную информацию с существующими источниками данных, чтобы убедиться в ее корректности перед дальнейшей обработкой.
- Автоматизация рабочих процессов: После проверки системы IDP могут инициировать определенные действия на основе данных, такие как направление документов на утверждение, обновление баз данных или инициирование платежных процессов.
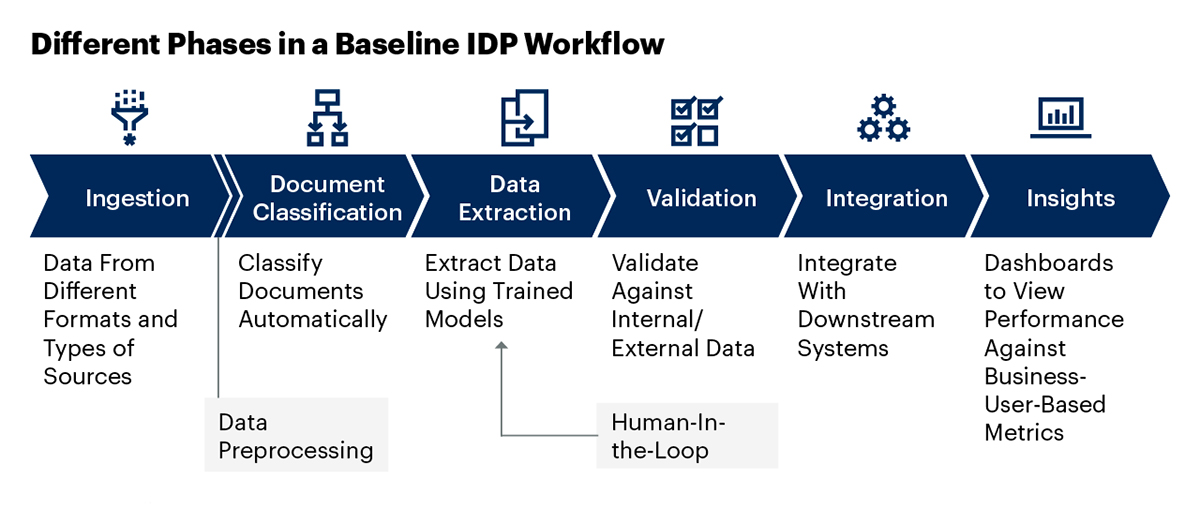
Как работает IDP
Процесс интеллектуальной обработки документов обычно следует за установленной серией шагов, которые позволяют компании автоматизировать свой документооборот:
- Ввод документов: Первый шаг — ввод документов в систему. Это может быть сканирование бумажных документов или загрузка электронных файлов.
- Извлечение данных: Затем система использует OCR и искусственный интеллект для извлечения соответствующих данных из документов. Этот процесс может включать имена, даты, адреса, суммы счетов и т.д.
- Классификация и маркировка: После извлечения данных система классифицирует документ на основе предопределенных категорий. Например, счета-фактуры могут быть помечены как «Счет-фактура», а контракты — как «Контракт».
- Проверка и обработка: После классификации документа система проверяет извлеченные данные, гарантируя их точность. Если все правильно, система переходит к следующим шагам рабочего процесса, например, к инициированию оплаты счета.
- Заключительные действия: На основе проверки данных система предпринимает необходимые действия, такие как отправка документа на утверждение, его архивация в нужном месте или выполнение автоматизированных транзакций.
Преимущества интеллектуальной обработки документов
Интеллектуальная обработка документов предлагает широкий спектр преимуществ, которые могут изменить подход предприятий к обработке документов. IDP автоматизирует повторяющиеся задачи, значительно сокращая время, затрачиваемое на процессы, связанные с документами. Например, счет-фактура, который раньше требовал ручного ввода данных, теперь может быть обработан за считанные секунды.
Человеческие ошибки — обычное дело при ручной обработке документов, будь то неверная интерпретация почерка или ввод неверных данных. IDP, работающий на основе искусственного интеллекта, обеспечивает точное извлечение и обработку данных, сводя к минимуму ошибки и обеспечивая согласованность. Автоматизация обработки документов также помогает сократить потребность в выполнении человеком трудоемких задач, что приведет к значительной экономии средств. Предприятия могут перераспределить человеческие ресурсы на более ценные задачи, повысив общую производительность.
IDP организует и хранит документы в цифровом формате, что упрощает их извлечение, распространение и управление. Это помогает компаниям лучше контролировать свои документы и обеспечивает соответствие нормативным требованиям. Ускоряя обработку документов, компании могут предложить более быстрое время ответа, повышая удовлетворенность клиентов. Например, более быстрая обработка претензий в страховой отрасли может привести к более довольным клиентам. Кроме того, системы IDP прекрасно масштабируются, что позволяет компаниям легко справляться с растущими объемами документов, не жертвуя эффективностью или точностью.
Применение интеллектуальной обработки документов
Структурированные данные имеют заранее определенную структуру, что облегчает их извлечение и анализ. Примерами структурированных документов являются формы, счета, квитанции, опросы и контракты, каждый из которых содержит ценные элементы данных, которые можно извлечь с помощью технологий, основанных на искусственном интеллекте. В отличие от структурированных данных, которые соответствуют заранее определенным форматам или схемам, неструктурированные данные не имеют четкой организации, что делает их сложными для извлечения информации вручную. Отдельной проблемой является сбор неструктурированных данных. Вследствие большого объема, разнообразия и сложности информации, это сложно делать. Тем не менее, извлечение информации именно из неструктурированных данных представляет собой важнейшую вещь в сфере управления информацией, так как просеивая огромные объемы данных, можно обнаружить значимую для бизнеса информацию. Такими данными могут быть, например, электронные письма, новостные статьи, юридические документы и научные работы.
Примером неструктурированных данных являются газетные статьи. Они часто содержат смесь текстового контента, изображений и метаданных, что затрудняет извлечение нужной информации вручную. Используя методы извлечения данных на базе искусственного интеллекта, можно автоматически анализировать газеты, извлекая такие важные сведения, как заголовки, даты публикаций, имена авторов и персонажей, содержание статей для цифрового архивирования и исследовательских целей. Юридические документы представляют собой еще один пример неструктурированных данных, которые можно эффективно анализировать, применяя технологии извлечения данных на основе искусственного интеллекта. Юридические документы, такие как контракты, соглашения и судебные документы, часто содержат плотный, сложный язык и замысловатое форматирование. Но из таких документов можно извлекать ключевые положения, пункты и даты, имена судей, подсудимых и ответчиков. И это лишь некоторые из примеров неструктурированных данных. С развитием цифрового мира могут возникать новые форматы, а уже имеющиеся форматы могут адаптироваться для включения в них новых неструктурированных типов данных.
IDP в области финансов и бухгалтерского учета
- Обработка счетов: Системы IDP могут автоматически извлекать данные из счетов-фактур, проверять их и запускать процессы оплаты.
- Управление расходами: Автоматизация обработки отчетов о расходах помогает компаниям эффективно отслеживать и управлять расходами.
- Автоматизация финансовой отчетности: IDP может помочь автоматизировать создание финансовых отчетов, сокращая объем ручной работы и повышая точность.
IDP в здравоохранении
- Управление медицинской картой: Системы IDP могут оцифровывать медицинские карты пациентов, делая их легкодоступными и обеспечивая при этом соблюдение правил здравоохранения.
- Обработка страховых претензий: Автоматизация извлечения данных из страховых претензий ускоряет процессы утверждения и уменьшает количество ошибок.
IDP в области права и соответствия
- Обзор и управление контрактами: IDP может оптимизировать обработку контрактов, извлекая ключевые положения, даты и условия для легкого анализа и управления.
- Управление документами соответствия: Нормативные документы можно классифицировать, маркировать и эффективно хранить, обеспечивая соответствие отраслевым стандартам.
IDP в розничной торговле и цепочке поставок
- Обработка заказов и управление запасами: IDP автоматизирует извлечение данных о заказах и обновляет системы инвентаризации в режиме реального времени.
- Управление поставщиками и поставками: Оптимизируйте рабочие процессы закупок за счет автоматизации контрактов с поставщиками и обработки платежей.
IDP в правительстве
- Обработка налоговых документов: IDP может помочь государственным учреждениям обрабатывать налоговые декларации, сокращая ручное вмешательство и повышая скорость обслуживания.
- Управление публичными записями: Автоматизация управления публичными записями помогает обеспечить удобство поиска и хорошую организованность.
IDP-инструменты извлечения данных из pdf
Самый часто встречаемый формат документов в бизнес-практике — pdf. В этом формате присылают счета-фактуры, резюме, годовые и квартальные отчеты. Большинство популярных редакторов документов умеет сохранять документы в pdf, поскольку это защищает их от редактирования. Поэтому мы рассмотрим инструменты для извлечения данных из таких файлов, которые также могут быть как структурированными, так и неструктурированными.
iText
iText — это мощная библиотека для манипулирования и извлечения данных, которая позволяет пользователям программно анализировать, изменять и извлекать данные из документов в формате pdf. С помощью iText организации могут автоматизировать процесс извлечения текста, изображений и метаданных из pdf. Одним из недостатков iText является его стоимость. По сравнению с другими инструментами для интеллектуальной обработки документов, лицензия на распространение iText является самой дорогой в этом списке. В зависимости от бюджета проекта, стоимость лицензирования может существенно повлиять на общую стоимость разработки.
GdPicture
GdPicture — еще один универсальный инструмент для извлечения данных из pdf, предлагающий широкий спектр функций для обработки документов и распознавания изображений. С помощью GdPicture разработчики могут с легкостью извлекать текст, изображения, таблицы и другие элементы из документов в формате pdf. GdPicture является наиболее сбалансированным решением, когда речь идет о точности распознавания и стоимости лицензирования. Стоит отметить, что базовая версия GdPicture может работать только с pdf-документами с текстовым слоем, поэтому для документов без текстового слоя вам придется либо перейти на другую версию GdPicture, либо использовать другие инструменты для извлечения данных.
Pdfplumber
Pdfplumber — это библиотека Python, специально разработанная для задач извлечения данных из pdf-файлов, которая предлагает широкие возможности для разбора и извлечения текстовых и табличных данных. К сожалению, полностью бесплатный Pdfplumber является наименее точным из всех инструментов в нашем списке. Так что не рекомендуется использовать Pdfplumber в проектах, где важна высокая точность.
OpenCV
OpenCV — это популярная библиотека компьютерного зрения, которая также может быть использована для задач извлечения данных из pdf, в частности для извлечения изображений, графиков и примитивов (основных структурных элементов документа, таких как вертикальные и горизонтальные линии, поля и т.д.). OpenCV — очень мощный инструмент в руках опытного ML-разработчика. OpenCV может решать сложные задачи по поиску и извлечению данных, обнаружению примитивов, извлечению и обнаружению как печатного, так и рукописного текста.
Azure Form Recognizer
Azure Form Recognizer — это облачный инструмент, предлагаемый Microsoft Azure для извлечения структурированных данных из pdf-форм и документов. Используя модели машинного обучения, Azure Form Recognizer может автоматически определять и извлекать ключевые поля данных из pdf-файлов. Azure Form Recognizer лучше всего работает с налоговыми формами, но может работать и с другими типами документов. Однако если вам нужно извлечь данные из неструктурированных документов или документов, отличных от налоговых форм, рекомендуется использовать другие инструменты для достижения более высокой точности распознавания.
MLPClassifier
MLPClassifier — это алгоритм машинного обучения, обычно используемый для задач классификации текста, включая извлечение данных из pdf. Обучая модели MLPClassifier на маркированных pdf-данных, организации могут разрабатывать индивидуальные решения для извлечения определенных типов информации из pdf-документов, таких как анализ настроения, распознавание сущностей или категоризация документов.
Amazon Textract
Amazon Textract — это полностью управляемый сервис OCR, предоставляемый Amazon Web Services (AWS), предназначенный для извлечения текста, таблиц и форм из отсканированных документов, включая pdf-файлы. Amazon Textract — отличный выбор для обработки структурированных документов, особенно pdf-файлов без текстового слоя. Этот инструмент отлично подходит для выполнения первого шага интеллектуальной обработки pdf-документов без текстового слоя — извлечения текста. А дальше уже можно подключать другие инструменты.
IRISXtract
Инструмент IRISXtract от компании Canon предоставляет ряд преимуществ для автоматизации обработки документов, включая сокращение рабочей нагрузки и расходов, повышение эффективности, ускорение бизнес-процессов, обеспечение бумажной обработки и возможность интеграции данных в другие системы. Эта интеллектуальная платформа на основе искусственного интеллекта автоматически классифицирует документы, извлекает необходимую информацию из структурированных и свободных форм, а также поддерживает работу с динамическими масками и проверку данных. IRISXtract способен извлекать данные как из структурированных форм, так и из документов свободной формы, благодаря сочетанию различных методов сбора данных, а конструктор форм Solution Designer позволяет легко настраивать процесс обработки и добавлять функции для работы со сложными документами.
ChatGPT
Все версии GPT, а также ChatGPT — вариант GPT, специально разработанный для разговорного искусственного интеллекта, также могут быть использованы для задач по извлечению данных из pdf. Популярная модель OpenAI отлично подходит для семантического поиска и интеллектуальной обработки документов, которая включает в себя постобработку извлеченных данных.
Среди известных игроков рынка интеллектуальной обработки документов, с которыми вы можете столкнуться, также можно назвать Azure Document Intelligence, Google Document AI, Snowflake Document AI, ABBYY, UiPath, Kofax, Dociphi (Quantiphi), Nanonets, Docsumo, Rossum и Docparser.

Выводы
Для каждой задачи и типа данных нужно подбирать свои инструменты анализа данных. Где-то может хватить бесплатной библиотеки, а где-то придется вложиться в лицензированное программное обеспечение, обладающее расширенным функционалом. По мере развития технологий искусственного интеллекта мы можем ожидать появления более надежных, точных и контекстно-зависимых систем обработки документов, способных обрабатывать все более сложные структуры документов. Впереди захватывающий путь, полный технологических прорывов и инновационных решений, которые обещают переосмыслить наше отношение к документам.



