



«Проблема в ажиотаже, в вере, что достаточно лишь собрать побольше информации, — и мы сотворим что-то волшебное. Нам следует помнить об одном: большие данные не лучше. Они всего лишь больше. И конечно, они не говорят сами за себя».
Карл Бергстром, Джевин Уэст.
«Полный бред! Скептицизм в мире больших данных»
А что не так с Big Data, спросят меня. В общем-то, с точки зрения чисто научного подхода, все так, а вот подача и восприятие подкачали. В сущности, в вопросе восприятия две проблемы — проблема растущего словаря с параллельной под-меной понятий и проблема индуктивной логики1. В чем проблема со словарем и подменой понятий?
Проблема в том, что нематериальные сущности не имеют ни веса ни объема и их невозможно пощупать, и Big Data, будучи такой технологией, тоже не является материальной сущностью. А потому все свойства приписаны ей нашим сознанием. И в зависимости от словаря и понятий этого словаря мы приписываем ей, возможно, и несуществующие качества, одним из которых является получение новых знаний, способных помочь нам развивать бизнес, из огромных массивов информации. Это заблуждение проистекает из более глубокого заблуждения о том, что из наблюдений можно выводить знания, то есть из индуктивной логики, которую ставили под сомнение и Платон, и Юм, и Кант, и Поппер, а эти философы, как ни крути, — золотой фонд человеческой мудрости, и прислушиваться к их мнению очень даже стоит.
Да и о каком знании мы вообще говорим? Кто-нибудь вообще над определением понятия «знание» задумывался? А стоило бы, ведь мы ищем такое «знание», которое поможет нам в ведении нашего бизнеса. Есть старое, платоновское, определение: «Знание есть разумное понимание причины явления». Есть современное: «Знание обычно описывается как информация, которая признана или усвоена человеком и способна влиять на его мысли, восприятие, понимание или действия. Это результат обучения, опыта, исследования или осознанного приобретения информации». Обратите внимание на фразу «…обычно описывается…». Это не определение, а простое описание. А теперь просто задумаемся, какое именно «знание» поможет нам в развитии бизнеса?
Будет выглядеть ужасно, но определение, которому более 2500 лет, когда еще Александр Филиппович не родился, оказалось самым адекватным для современных условий, и действительно никакая статистика и никакое количество наблюдений2 не помогут нам заглянуть в будущее, и только понимание причины явления позволяет это сделать, а это именно то, что требуется бизнесу для успешного планирования и для взвешенного принятия решений.
«…все, что может быть сказано, должно быть сказано четко…»3
И именно четкость мышления и высказываний должна нам помочь разобраться с Big Data и с ее пользой для бизнеса. С главным, если можно так выразиться, свойством, заключающимся в том, что огромные массивы информации позволяют нам приобретать новые знания, которые помогают в развитии бизнеса, мы разобрались. Проблема разлагалась на два вопроса:
- «знания» в каком понимании?
- принципиальная невозможность обобщать сингулярные высказывания.
Таким образом, получается, что огромные массивы информации не позволяют нам получать новые знания, способные помочь в ведении бизнеса.
Думается, настало время дать определение тому, что называют Big Data, но прежде уточним некоторые понятия, которые нам понадобятся в дальнейшем.
- Знание — понимание причины явления (события);
- Гипотеза — предположительное знание;
- Теория — не опровергнутая в результате разносторонних проверок гипотезы.
А теперь вернемся к Big Data. Не будем приводить полное определение. Его каждый может найти сам. Остановимся на трех V в определении:
- Volume (объем) — очень важное качество и в этом наше сознание нас не обмануло. Действительно, при стремлении количества наблюдений к бесконечности, наблюдения стремятся к нормальному распределению, получив которое мы легко можем просчитать вероятность, которая в случае бизнеса вполне заменяет гипотезы, имея которые (гипотезы или вероятности) мы можем строить достоверные прогнозы.
- Velocity (скорость) — достаточно приятное качество, согласитесь. Гораздо приятнее получить ответ быстро, во всяком случае, пока ты не забыл вопрос.
- Variety (разнообразие) -а вот здесь надо быть осторожнее. Наше сознание нас обмануло. На самом деле забавно наблюдать, как всеобщее заблуждение (речь идет о KYC — Know Your Customer) превращается в непререкаемую истину для масс.
Рассмотрим поподробней это качество (Variety) с позиции KYC. Следует отметить, что парадигма KYC уходит корнями в детерминизм Канта4, в котором речь идет о том, что все события в природе и в мире подчиняются законам причинности. В общем-то, это верное рассуждение для своего времени. Но тут следует заметить, что высказано оно было до появления квантовой механики, которая показала, что живем-то мы в квантовом мире и любое явление носит вероятностный характер. Это, во-первых. Но есть и во-вторых, и даже в-третьих. Во-вторых, мы никогда не узнаем всех причинно-следственных связей. И тут может раздаться радостный крик: «Так именно такие связи позволяют найти Big Data»! К этому вопросу мы вернемся позже, а пока… В-третьих, мы уже отмечали, что относительно достоверные прогнозы можно строить только на базе гипотез. На самом деле это не совсем так. В ситуации, когда высказывание гипотезы невозможно, как это обычно бывает в бизнесе, вместо гипотезы вполне допустима вероятность. И вот именно вероятностный подход мы детально рассмотрим, естественно, сквозь призму KYC, и поможет нам в этом такая математическая дисциплина, как комбинаторика5.
Рассмотрим гипотетический пример6. У нас имеется 1 млн. клиентов, и мы хотим посмотреть распределение по среднему чеку. Далее показано, как будет выглядеть такое распределение.
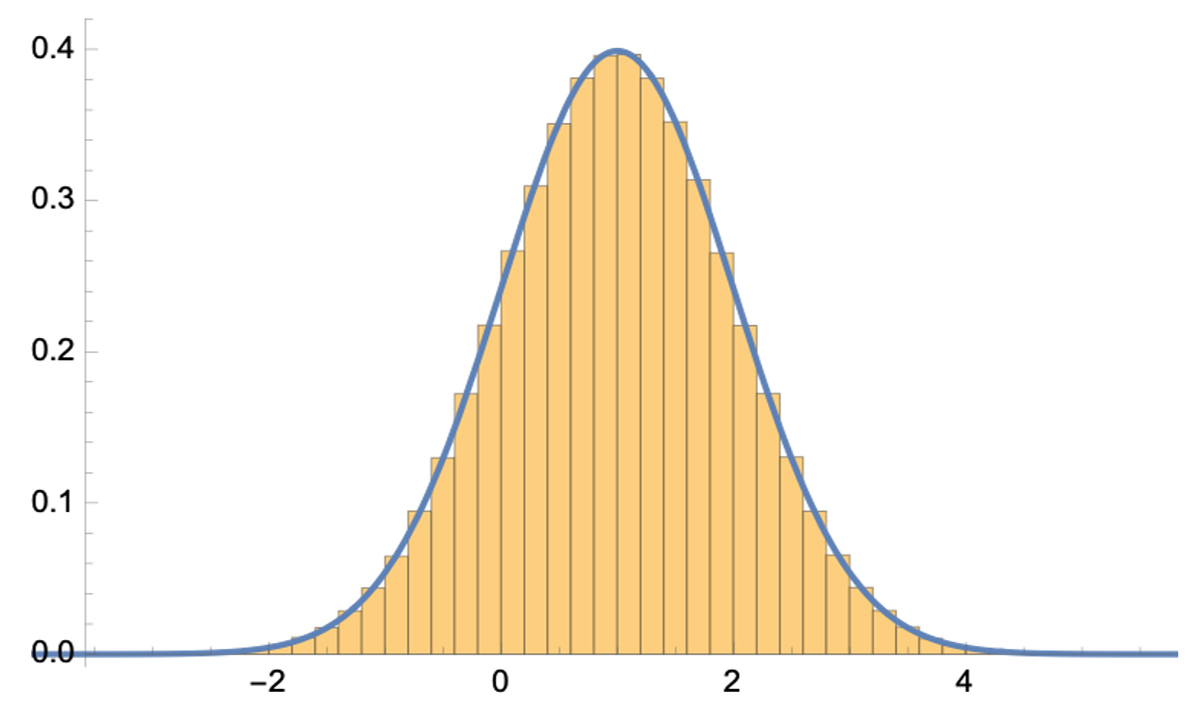
Синей линией отображено нормальное распределение. Как видно из представленного графика, мы получили именно его, и, имея на руках нормальное распределение (в принципе, любое), мы легко можем просчитать вероятность любого события. Но поскольку мы взяли полную выборку, у нас полностью отсутствует какая-либо персонификация, то есть мы ничего не знаем о поведении клиента с определенным набором признаков.
Было решено персонифицировать информацию для целей маркетинговых исследований, для чего использовали 8 признаков. У каждого признака несколько вариантов (от двух до четырех). И тут же получилось, что в каждой новообразованной группе примерно по 50 клиентов. Вела себя такая группа в среднем следующим образом:
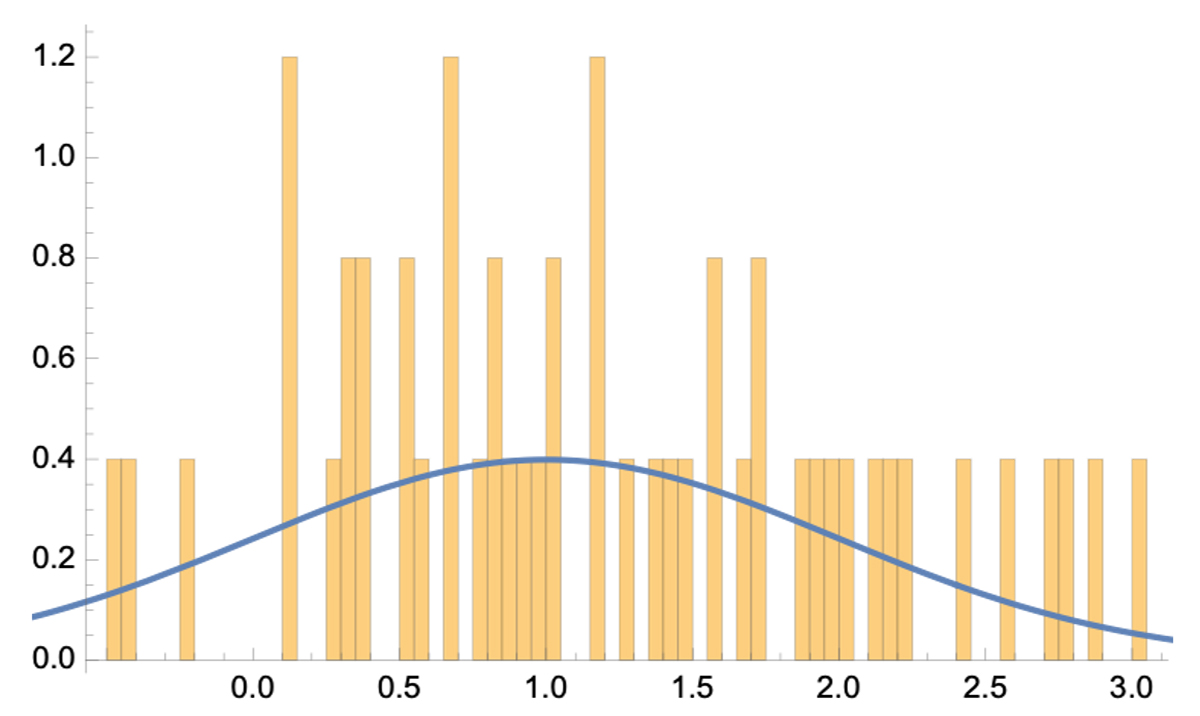
как видим, при такой картине ни о каком распределении речи быть не может, равно как и о вероятности. Это явление называется «проклятием размерности». Причем, речь идет далеко не о Big Data. У нас всего 8 признаков, что далеко не Variety. А что будет при действительно большом наборе характеристик, можно легко посчитать.
Вывод: Чем больше мы знаем о своем клиенте, тем менее достоверен прогноз, касаемый его поведения. При достоверном же прогнозе мы о клиенте не знаем ничего.
Думаю, с Variety все ясно, и дополнительных комментариев не требуется. А теперь посмотрим на «обнаружение скрытых закономерностей». Но прежде чем приступить к конкретному рассмотрению, следует отметить один общий для всех методов момент. В поиске закономерностей мы, как правило, рассматриваем пары, то есть функции одного аргумента, или, говоря проще, мы рассматриваем вариант зависимости «A» от «B», где «A» и «B» — любые переменные. Так вот, если мы имеем действительно Big Data, состоящую из, допустим, 200 переменных, то число возможных пар из 200 переменных составляет примерно 20000 (19900, если быть точным). Кому не лень, может пересчитать. В случае трех и более переменных ситуация становится гораздо хуже, и счет там пойдет уже на десятки миллионов.
Итак, что же мы здесь имеем? Во-первых, кластеризацию. С этим вопросом мы уже разобрались. Во-вторых, — регрессию. Регрессия была создана сэром Фрэнсисом Гальтоном7 и предназначалась для нахождения взаимосвязей между двумя переменными. Это понятие работает только тогда, когда имеется аналитический вид формулы, описывающей такую взаимосвязь путем нахождения неизвестных коэффициентов, входящих в эту формулу. Да, может сработать, если мы имеем формулу, описывающую зависимость, но при этом следует заметить, что из 20000 возможных пар всегда можно наткнуться на случайную, логически ничем не обоснованную, зависимость. В-третьих, есть еще машинное обучение, но это та же кластеризация. В-четвертых, визуализация. И кому под силу обработать на предмет визуального нахождения зависимости 20000 графиков? Я уже не говорю о более сложных многомерных зависимостях. Ну и наконец, корреляция. Корреляция — это не причинно-следственная связь, а просто… корреляция и ничего больше. И никакая это не зависимость, а в 20000 парах найти случайные корреляции штука весьма и весьма вероятная.
Итак, огромные многомерные массивы информации, без имеющихся для них логически оправданных гипотез, не позволяют находить ни скрытых ни открытых взаимосвязей.
Выходит, Big Data бесполезна? Вовсе нет, она бесполезна вне научного подхода, вне логически обоснованных гипотез. Только научный подход и гипотезы, логически обоснованные, могут придать ей истинную ценность. А у кого они есть, такие гипотезы?
1 Индуктивная логика — это раздел логики, который занимается обоснованием общих утверждений на основе конкретных наблюдений и опыта.
2 С логической точки зрения далеко не очевидна оправданность наших действий по выведению универсальных высказываний из сингулярных, независимо от числа последних, поскольку любое заключение, выведенное таким образом, всегда может оказаться ложным. Сколько бы примеров появления белых лебедей мы ни наблюдали, все это не оправдывает заключения: «Все лебеди белые». К. Р, Поппер. «Логика Научного Исследования».
3 Л.Витгенштейн. «Логико-философский Трактат».
4 «Критика Чистого Разума».
5 Раздел математики, который изучает комбинаторные структуры, такие как перестановки, сочетания и размещения, а также методы их подсчета и анализа.
6 На самом деле пример не совсем гипотетический. Он взят из реальной жизни, просто данные искажены, но с сохранением имевшихся закономерностей. В частности, они нормированы на единицу.
7 Сэр Фрэ́нсис Га́льтон (16 февраля 1822 г., Бирмингем, Уэст-Мидлендс, Англия, Великобритания — 17 января 1911 г, Хейзлмир, Суррей, Англия, Великобритания) — английский исследователь, географ, антрополог, психолог, статистик, основатель дифференциальной психологии и психометрики, а также основоположник учения евгеники, которое было призвано бороться с явлениями вырождения в человеческом генофонде.
Автор: Фаруг Д.Муганлинский




