



Вычислительные ускорители NVIDIA Tesla прочно заняли своё место везде, где требуется высокая вычислительная производительность: от биржевого анализа до научных расчётов. Ими комплектуются специальные серверы, на их базе строятся вычислительные суперкластеры. Как пишет 3DNews со ссылкой на официальный источник, секрет успеха NVIDIA в этой области — поддержка всех современных как закрытых (CUDA), так и открытых технологий (OpenCL, DirectCompute). И в одной из предыдущих новостей мы уже сообщали, что компания готовит к запуску новые модели ускорителей Tesla, как на базе новой архитектуры Maxwell, так и на основе проверенной временем архитектуры Kepler. Особняком в этом списке стояла модель Tesla K80, которая должна была стать вторым двухпроцессорным вычислительным ускорителем NVIDIA после устаревшего D870.

Так и случилось. Компания опубликовала официальный анонс Tesla K80, наиболее мощного ускорителя в серии на сегодняшний день. Как и ожидалось, он получил два процессора, но не GK110, как можно было предположить, а совершенно новые GK210, которые, впрочем, производятся с использованием того же 28-нанометрового техпроцесса TSMC. Двухпроцессорные графические карты — это всегда компромисс, и то же в полной мере относится и к вычислительным ускорителям. Если один процессор GK110 на борту Tesla K40 имеет 2880 активных поточных процессоров, то GK210 в конструкции Tesla K80 были несколько усечены в конфигурации и получили по 2496 процессоров на чип. Это позволило уложиться в 300-ваттный теплопакет и сделать систему охлаждения полностью пассивной, рассчитанной на продув силами вентиляторов, установленных в корпусе сервера. Их там, как правило, немало и они обеспечивают мощный воздушный поток, поскольку о тишине особенно заботиться не надо.

Не обошлось и без снижения тактовых частот: ядра Tesla K80 работают на частоте всего 562 МГц в базовом режиме и 875 МГц — в турборежиме. Но в данном случае количество бьёт качество: почти 5 тысяч поточных процессоров, а точнее, 4992, работая в турборежиме, легко выдают 2,91 терафлопса вычислительной мощности в режиме двойной точности. В обычном режиме этот показатель снижается до 1,87 терафлопс, что всё равно больше, чем может дать Tesla K40 в турборежиме (1,66 терафлопс). При этом карта имеет стандартную компоновку: один слот PCIe x16 и двойная высота, что незаменимо для компактных систем, от которых, тем не менее, требуется высокая вычислительная мощность. А в режиме одинарной точности вычислений показатели новичка выглядят ещё внушительнее: 8,74 и 5,6 терафлопс соответственно. Быстрая межпроцессорная шина NVLink позволяет избежать традиционных для NUMA-систем «бутылочных горлышек».
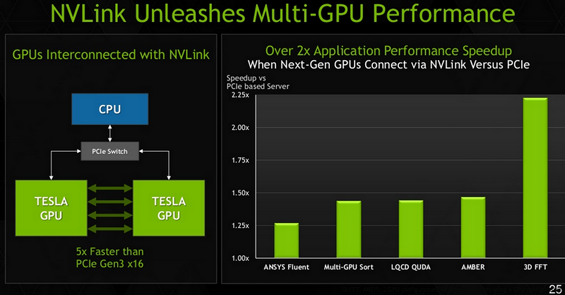
Не подкачала и подсистема памяти: на борту NVIDIA Tesla K80 установлено сразу 24 гигабайта быстрой памяти GDDR5, что является своеобразным рекордом: даже AMD FirePro W9100 располагает всего 16 гигабайтами. И это честные 24 гигабайта, ведь, в отличие от игровой технологии SLI, данные в памяти первого GPU не должны дублироваться в блоке памяти второго GPU. Надо ли объяснять, что объём памяти в массивных вычислениях играет далеко не последнюю роль? Не забыта и пропускная способность: совокупная производительность подсистемы памяти Tesla K80 достигает 480 Гбайт/с, по 240 Гбайт/с на каждый процессор. Это делает новинку идеальным решением практически для любой сферы, где необходимы массивные вычисления — от астрофизики, генетики и квантовой химии, до анализа больших массивов данных и систем «глубокого машинного обучения». Всего ускорители Tesla могут работать более чем с 280 приложениями и программными пакетами.
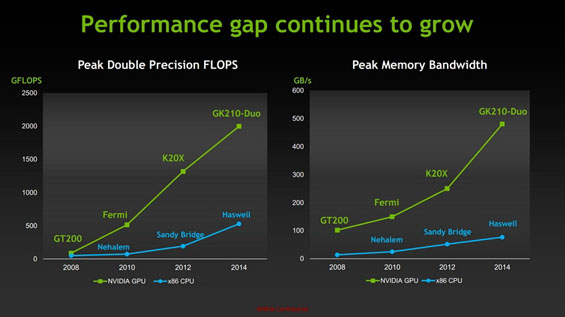
По утверждению NVIDIA, ускоритель Tesla K80 на порядок (в 10 раз) опережает самые лучшие традиционные процессоры в наиболее распространённых научных и инженерных программных пакетах, таких как GROMACS, AMBER, LSMS или Quantum Espresso. Если вспомнить о тепловых и электрических характеристиках, то оказывается, что K80 очень сильно превосходит обычные ЦП и в плане энергоэффективности: 18-ядерный Intel Xeon E5-2699v3 имеет теплопакет в районе 145 ватт, а NVIDIA Tesla K80, как уже упоминалось выше, — всего около 300 ватт, то есть как пара таких Xeon. При этом последний несравнимо быстрее. Итак, следует заключить, что идея GPGPU, то есть «вычислений на базе графических процессоров», отлично прижилась в современной науке, инженерии и экономике. Так считают и лучшие умы планеты.
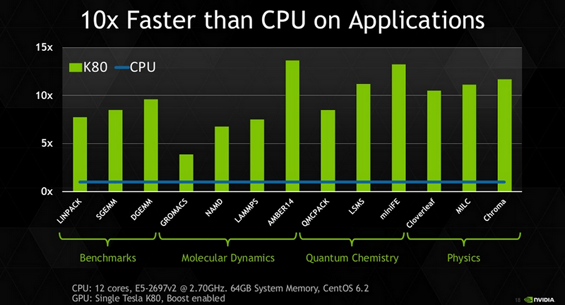
В частности, Вольфганг Нейджел (Wolfgang Nagel), директор центра информационных услуг в Дрезденском Техническом Университете, говорит, что учёные используют ресурсы суперкомпьютера Taurus, построенного на базе GPU NVIDIA, для таких задач, как поиск и разработка методов лечения рака, изучения клеток в реальном времени и даже исследования астероидов в рамках прогремевшего недавно на весь мир проекта ESA «Rosetta». А появление новой мощной, но при этом компактной и экономичной модели ускорителя NVIDIA Tesla непременно приведёт к созданию ещё более мощных и эффективных суперкомпьютеров, от чего выиграет и наука, и человечество в целом. Поставки ускорителя NVIDIA Tesla K80 уже начались, подробнее с ним можно ознакомиться в соответствующем разделе веб-сайта NVIDIA, а для скептиков существует даже бесплатная возможность опробовать GPGPU в деле.





